Compte-rendu de l'atelier IA du 30 janvier 2025 (Frédéric Clavert)
Introduction des Ateliers IA par Marcello Vitali-Rosati
L’idée de ces ateliers est de commencer échanges et réflexions communes sur l’implémentation d’algorithmes de ce qu’on appelle l’IA dans nos pratiques d’écriture et de publications d’articles scientifiques.
Dans la communauté DH, la réflexion sur l’implémentation d’algorithme remonte à 70 ans. Bien que l’introduction des transformers ait apporté des changements, on ne peut pas parler d’une révolution. Notre objectif avec cet atelier est de s’éloigner de la généralité que "IA = ChatGPT" et de la tendance actuelle à l’adoption d’applications mainstream sans réflexion.
Ces ateliers se veulent être un lieu de réflexion sur la théorie et les questions infrastructurelles liées à l’implémentations de technologies relevant de l’IA. C’est aussi l’opportunité de réflechir aux besoins sur ce sujet et potentiellement de financer des projets pilotes et expérimentations dans le cadre du partenariat Revue3.0.
Présentation par Frédéric Clavert de la fonctionalité explain code du JDH
Le Journal of Digital History, est une revue initiée en 2020, avec une première publication en 2021. L’intégration de technologies de l’IA y a davantage été pensé pour le lecteur que pour les auteur⸱ice⸱s.
Articles multicouches (multilayers articles):
- niveau narratif (texte)
- herméneutique (approche critique sur les méthodes)
- code ou data
Format : Jupyter notebook (format didactique avec cellules de code et markdown). Les différentes couches sont différenciées avec un système de tag.
{kind=link}
{kind=link}
Possibilité d’exécuter l’article sous mybinder pour tester les hypothèses de l’auteur⸱ice.
{kind=link}
Alternative : récupérer le code source sous Github.
Problématique de reproductibilité dans tous les cas.
Nouveau design (phase béta): couche supplémentaire avec "data&code".
{kind=link}
Dernières intégrations :
- Possibilité d’exécuter le code directement dans l’interface de la revue (intégration de mybinder dans la page de l’article).
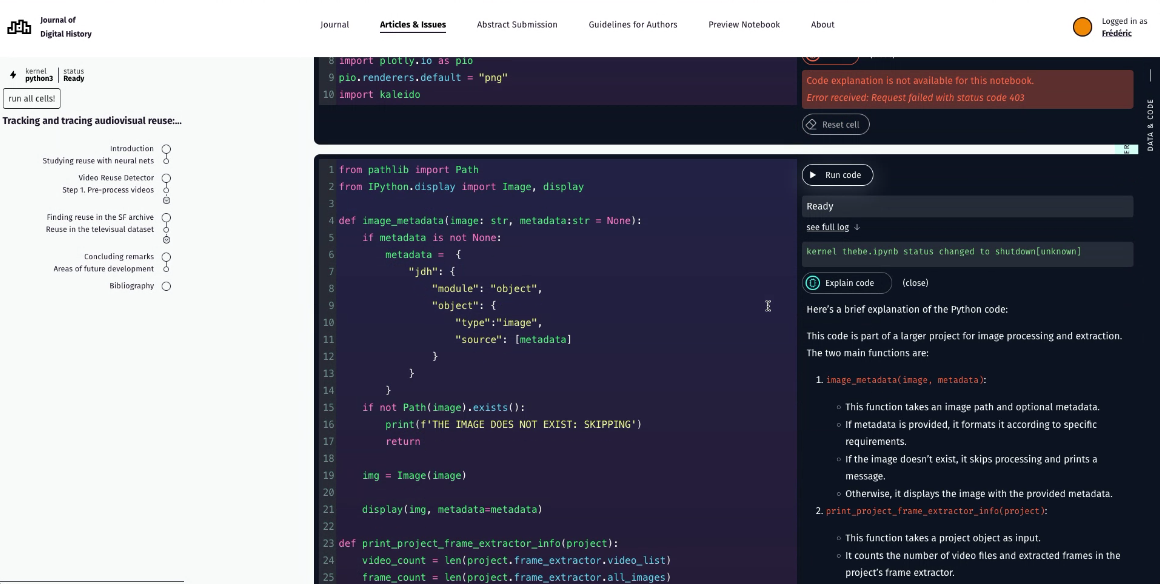
- Explain code : fonctionnalité IA permettant d’avoir une explication du code en temps réel.
- Utilisation de modèles Open Source comme Llama via Groq.com.
- Intérêt : l’explication fournie par les auteur⸱ice⸱s ne sont pas toujours explicites.
- Prompt : expliquer à un débutant le code de la cellule → orienté lecteur·trice. Prompt exact : "PYTHON_BEGINNER": "You are a helpful assistant to explain Python code easily. You reply with very short answers.". Exemple de réponse générée sur une portion de code.
{kind=link}
Intégrations à venir :
- fonctionnalité lecteur : LLMs pour rédiger les résumés des articles
Article en illustration des fonctionnalités :
Eriksson, M., Skotare, T., & Snickars, P. (2024). Tracking and tracing audiovisual reuse: Introducing the Video Reuse Detector. Journal of Digital History, 3(1). https://doi.org/10.1515/JDH-2024-0009?locatt=label:JDHFULL
Résumé sur la couche narrative et non la couche herméneutique (view renderer)
Comparaison de plusieurs modèles laisse voir que Gemini est le plus efficace pour ces tâches.
Elisabeth Guerard : ces fonctionnalités sont pour le lecteur, mais aussi pour les reviewers & technical reviewers
Enquête usage IA @C2DH : constate que tout le monde utilise ou va utiliser des IA génératives. Fréquence d’utilisation quotidienne ou hebdomadaire en majorité. Enquête d’il y a quelques mois : principalement ChatGPT et Microsoft Copilot/Github car fourni par l’université.
Discussion
Servanne Monjour : Quel est le processus de validation des resultats fournis par l’IA ?
Elisabeth Guerard :
- Comparaison du résumé généré par l’IA avec l’abstract fourni par l’auter⸱ice.
- Pas de protocole de validation pour la fonctionnalité « explain code ».
Marcello Vitali-Rosati :
- Le problème de la validation du code expliqué par un algorithme probabiliste c’est que l’on tombe dans le paradigme de la vraisemblance et plus de la vérité/vérification.
- Exemple de notebookLM qui fait du RAG (Retrieval Augmented Generation) avec Gemini : les résultats du RAG ou de l’explication de code sont d’un tel niveau de qualité que pour comprendre s’il y a une divergence avec l’intention, il faut être spécialiste.
- Comment distinguer "hautement ressemblant" de "vrai" ? On assiste à un changement de paradigme en faveur du vraisemblant.
Frédéric Clavert : Les explications sont à destination de débutants c’est-à-dire qu’elles offrent une amorce de compréhension pour des personnes sans ou avec une faible littératie numérique.
Il ne faut pas considérer ces systèmes comme donnant une réponse définitive.
Le but de l’outil devrait être de la maïeutique probabiliste.
L’interaction avec un chatbot est une discussion qui n’a pas de valeur sociale.
Nicolas Sauret : Les chatbots imposent un design (mode conversationnel) : on a mimé une discussion sociale alors que ce n’est pas le cas -> des rflexions sont nécessaires sur ce point.
Aurélien Barra : Question d’interface, métaphore de la discussion fait partie du succès de ces outils. Dimension oraculaire (clic→réponse).
Réponse : Les réponses à explain code vont être différentes à chaque requête mais vont rester malgré tout souvent très similaires.
Aurélien Berra :
- La nouvelle interface fournit un cadre sur lequel les éditeur·ice·s n’ont pas la main : il s’agit finalement d’une 3eme instance d’interprétation (éditeur/auteur + IA).
- Pourquoi est ce qu’on veut comprendre le code ? Que peut-on retirer de l’explication sur des éléments qui resteront toujours triviaux.
Frédéric Clavert :
- L’explication fournie pousse le lecteur à accroitre sa littératie numérique.
Aurélien Berra :
- Est-ce que les outils IA ne pourraient pas aider l’équipe d’édition à respecter les critères d’acceptation ?
- Pourrait-on mettre au point un outil pour détecter du code ou du texte généré automatiquement ?
Frédéric Clavert :
- Concernant l’appui à l’édition et aux critères d’acceptation les critères sont assez larges (par exemple, pas de nombre de caractères)
- Question d’évaluation du code plus difficile. Pas de garantie que les évaluateurs soient capable d’évaluer le code non plus.
- Question des droits d’auteurs / LLM : ne se règle pas au niveau d’une revue
- Détection de l’utilisation d’iA : un copier-coller est un acte auctorial.
le vrai travail consiste à dialoguer avec l’ia : validation après modification.
Nicolas Sauret : Pourquoi chercher une "interface chatbot" quand un texte généré en amont et statique et intégré dès publication peut être suffisant ?
et par ailleurs : quid d’une fonctionnalité de conversation avec l’article ?
Frédéric Clavert : L’outil est encore en phase de reflexion, notamment sur l’usage qui est fait du bouton "explain code". Déjà le fait d’appuyer sur le bouton créé une distinction avec ce qui est écrit par l’auteur·ice.
Elisabeth Guerard : C’est aussi le souhait des développeurs d’expérimenter avec l’intégration d’une API Flask et de jouer avec les technos actuelles.
Servanne Monjour : L’outil développé pour les lecteur·ice.s mais qui sont ces lecteurs, quels éléments statistiques avons-nous sur le lectorat ?
Frédéric Clavert : Le JDH a des données sur son lectorat mais pas centrée sur la fonctionalité IA. Ce que l’on sait c’est que le temps passé sur une page/article est de 7 à 9 minutes en moyenne contrairement à 1,5 min en moyenne sur le web. Ce qui signifie que les lecteur⸱ice⸱s restent et lisent. Nouvelle version (3) appréciée.
Elisabeth Guerard (dans le chat) : Grâce à Matomo., on peut à présent tracker les liens externes, ce que l’on ne pouvait voir avec Analytics, l’usage de MyBinder a pu être vu.
Outils cités
Mybinder : https://mybinder.org/ (génère des jupyter notebooks à partir d’un repo Git)
Groq : https://groq.com/ (serveur pour de l’inférence AI)
Matomo : https://fr.matomo.org/ (alternative à Google Analytics qui permet de tracker aussi les liens externes utilisés par les utilisateurs de son site)