Progression du projet IEML pour le balisage d'articles en SHS
Le 01 avril 2025, Alexia Schneider
Description du projet
Le projet a pour objectif d'explorer les potentialités du langage artificiel IEML, créé par Pierre Lévy, pour les revues en SHS.
L'enjeu central est celui de la maîtrise de l'information produite et diffusée : à l'heure où les modèles statistiques dominent les systèmes de recherche d'information comment définir sans ambiguité un cadre sémantique sans restreindre ses données à un cadre ontologique précis ? IEML en tant que matrice d'explicitation sémantique dont les règles syntaxiques permettent de produire des ontologies avec une grande flexibilité, est un langage prometteur pour répondre à cette problématique.
Cette approche théorique engage la question de la découvrabilité, de la transmission de la littérature savante et de manière plus fondamentale, interroge la modélisation du sens.
Contributions attendues
L'objectif du projet est d'intégrer un système de modélisation sémantique en IEML à l'outil Stylo afin de proposer une de visualisation alternative et complémentaire à l'indexation par mots-clés en langue naturelle ou dans des langages contrôlés du Web Sémantique.
Le livrable attendu est un prototype d'anotation sémantique automatique.
Étapes du projet réalisées
Mise en place
Mise en relation entre les différents membres du projets (Pierre Lévy et Marcello Vitali-Rosati à la direction, Alexia Schneider pour l'exécution).
Prise en main des librairies développées pour l'exploitation d'IEML : dictionnaire et parseur en C++ développé par Louis van Beurden. Des problèmes de compilation ont notamment retardé cette étape. Un nouveau parseur en Python est en cours de développement pour une meilleure intégration d'IEML aux besoins du projet.
Définition de la problématique à partir d'un cas pratique
Constitution d'un corpus d'articles et de mots-clés associés. Articles de la revue Sens public avec leurs mots-clés. Extraction des mots-clés en Dublin-Core des mêmes articles via Isidore.
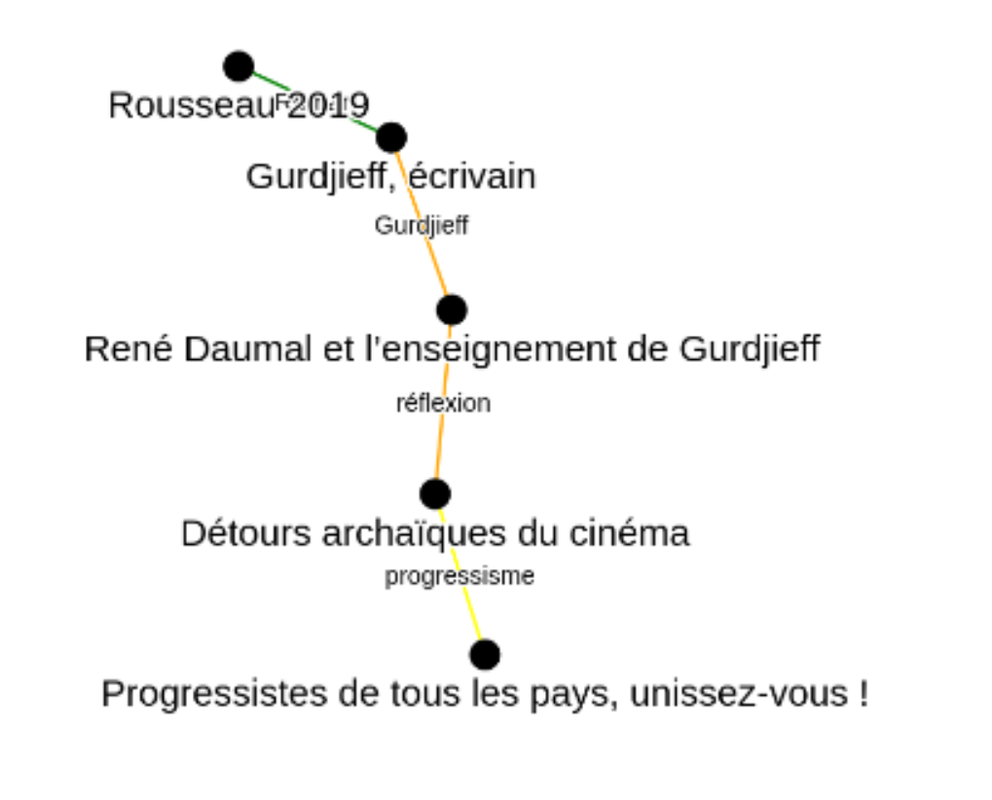
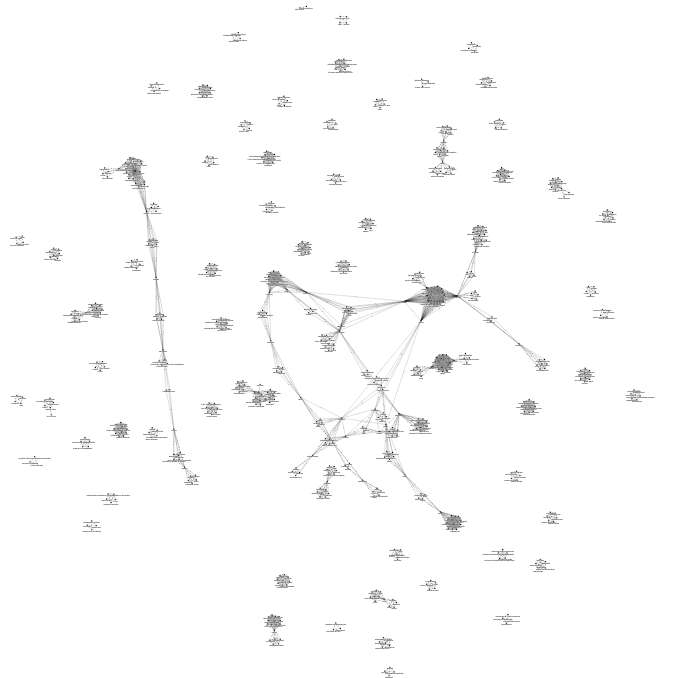
Création d'une stratégie "baseline" visant à mettre en relation les articles à partir des mots-clés existants sous forme d'un graphe de réseau. La figure ci-dessous illustre la logique relationnelle traditionnelle à partir des mots-clés soit en langue naturelle, proposés par la revue (jaune), soit ceux ajoutés par Isidore (orange), soit ceux ajoutés en Dublin Core par Isidore (vert).
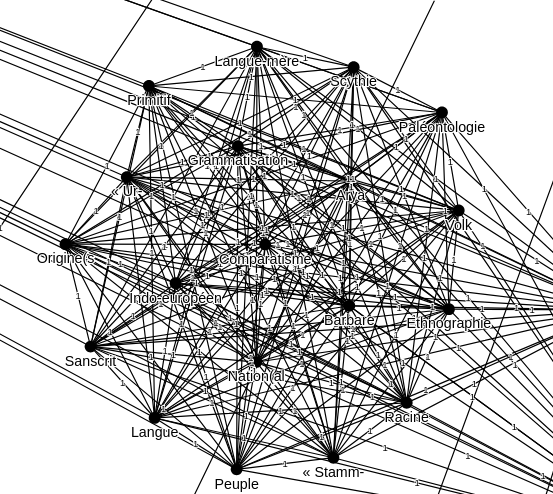
Visualisation de la baseline. Illustration de la problématique : quel sens peut émerger de la mise en relation d'articles ? Comment expliciter des relations existantes comme dans le cluster de mots-clés ci-dessous?
Expérimentations avec IEML
"Traduction" ou mapping en IEML des mots-clés du corpus. Premiers essais sur un nombre réduit de champs sémantiques (pages "sciences humaines et sociales" du dictionnaire).
Utilisation du parseur de Louis van Beurden pour établir les relations entre les mots-clés traduits en IEML.
Ces stratégies de mise en relation ne donnent pas davantage de sens aux relations observées.
Conclusion des premières étapes
La construction d'un parseur nécessite une compréhension solide de la logique du langage, ce qui demande du temps, d'autant plus que IEML est un langage complexe qui oblige à penser en dehors des paradigmes conceptuels habituels en programmation.
Ces premiers mois de recherche ont été important pour définir la problématique propre à ce langage et à la question de la représentation du sens dans un corpus de mots-clés partiellement décontextualisé.
Perspectives
Une piste de réflexion est de repenser la mise en relation non plus comme un réseau statique mais plutôt comme un tableau voire comme un échiquier sur lequel les termes se déplacent en mouvement sémantique.
De même, tirer partie d'IEML passe par une mise en relation qui n'est pas top-down (du "paradigme racine" aux termes qui le compose) mais qui s'intéresse plutôt au voisinage.